Deep learning based approach for relation extraction using NLP - RelEx (DL-based)
 Sentence-CNN
Sentence-CNNOur deep learning-based approach determines whether a relation exists between two entities using Convolutional Neural Network (CNN). Our approach includes three CNN architectures.
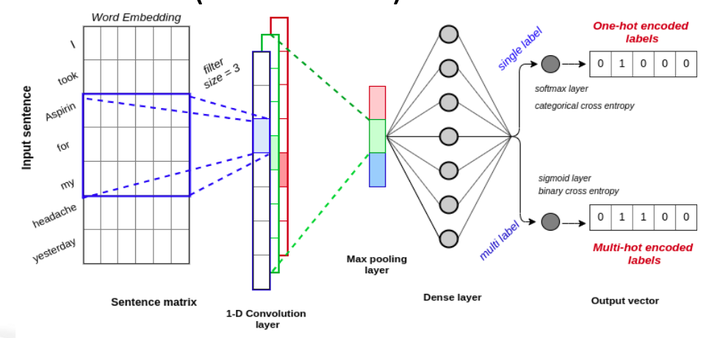
Single-label Sentence-CNN: In this architecture, each relation consists of a pair of entities. The Sentence-CNN learns the relation representation for the entire sentence as a whole. First, we identify the sentence where each relation is located and extract the sentence and we feed it into a CNN for learning. Second, we apply the convolution layer on the sentence and learn the local features from the embedding vectors obtained from each word of the sentence. 1D convolutions compute the weighted sum of the features and select a certain combination of features. Next, we apply the max-pooling layer to extract the most important feature from the entire sentence which is called the global feature as it is considered over the entire sentence. The max-pooling layer also helps in reducing the dimensionality of the input and discarding the features that do not contribute to the classification. Then we unstack the volume into a flat vector before feeding it into the fully connected feed-forward layer. Finally, the fixed-length vector is fed into a softmax (fully-connected) layer to perform the classification. Classification error is then back-propagated ,and the model is re-trained until the error is minimized. The weights of the matrix and bias are the parameters that get tuned until the optimized model is obtained. One of the beneficial properties of CNN is that it preserves the spatial orientation; in this case, the sequence of the words in the sentence.
Multi-label Sentence-CNN: Often in machine learning tasks, there can multiple possible labels for one instance that are not mutually exclusive. This is called a multi-label classification problem. In RE, this happens when an instance can contain more than a single set of relations between multiple entities. To address this, we modified the Sentence-CNN which predicted a single-label for an instance to predict multiple labels for an instance. As shown in Fig~\ref{fig_CNN_2}, when the multi-label flag is enabled the system outputs multi-hot encoded labels. The Multi-label Sentence-CNN is constructed differently in the following aspects: Loss function, Choice of the output layer, Multi-hot-encoding of labels. The figure shows how the multi-lable Sentence-CNN differs from the Single-label Sentence-CNN.
Segment-CNN: In the Sentence-CNN architecture, each relation is represented by an entire sentence and does not capture the positional information of the entity pairs but in Segment-CNN, the sentence is divided into segments and trained by separate convolutional units. We use this approach as our base architecture to compare the performance of our multi-label Sentence-CNN. Based on where the entities are located in the sentence, we divide the sentence into segments. Different segments play different roles in determining the relation. A sentence is explicitly segmented into five segments: preceding - tokenized words before the first concept, concept 1 - tokenized words in the first concept, middle - tokenized words between the two concepts, concept 2 - tokenized words in the second concept, and succeeding - tokenized words after the second concept.
Samantha (Darshini) Mahendran
Graduate Research Assistant
My research interests include distributed robotics, mobile computing and programmable matter.